IBM Cloud Pak for Data (CP4D) on AWS Modernization Workshop > Governance Lab > Introduction > Reference Architecture
Data Access & Governance Reference Architecture.
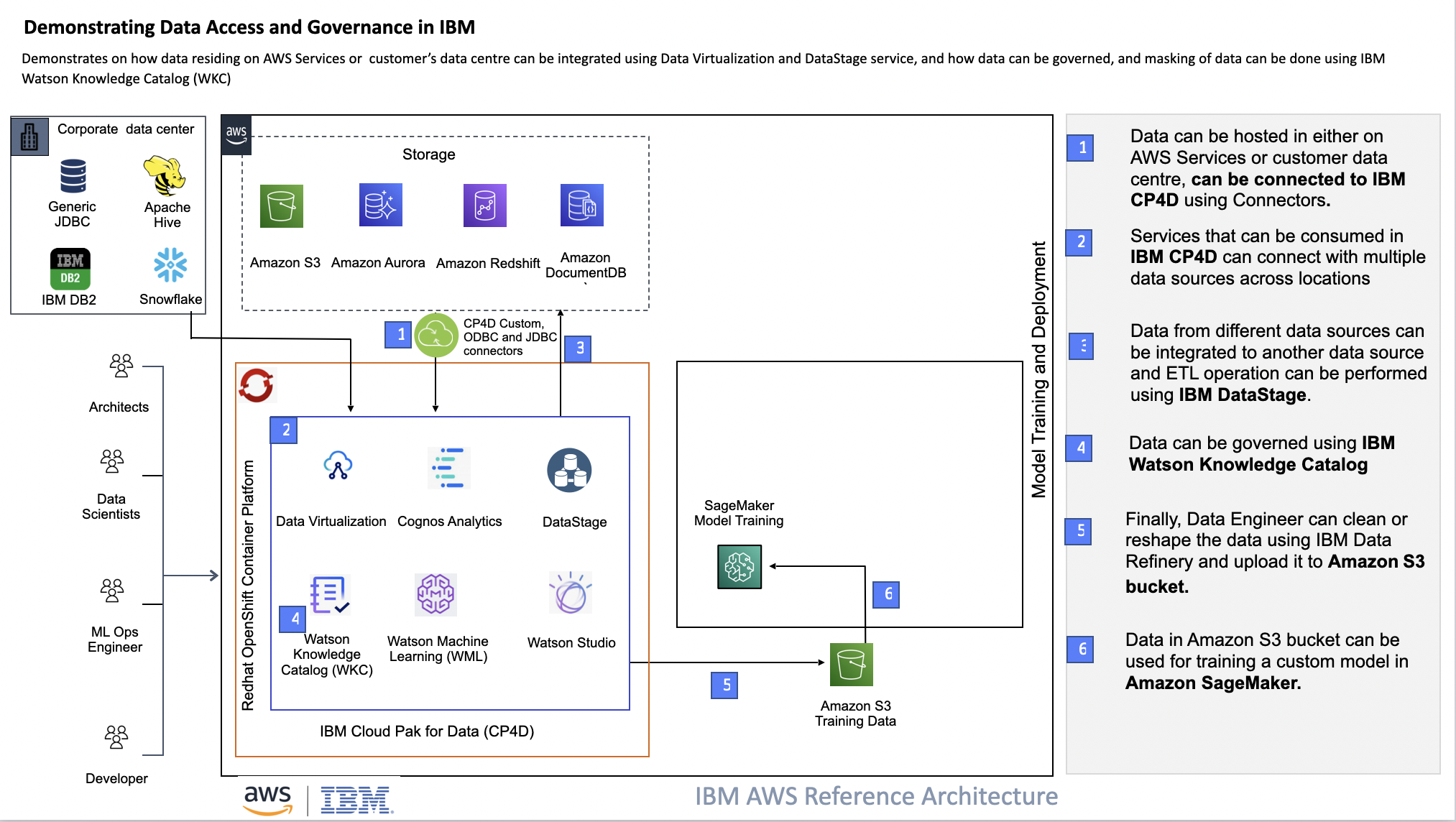
Flow
- Create external connection between external data sources (eg. Amazon S3, and Amazon Aurora PostgreSQL) and IBM Cloud Pak for Data.
- Use IBM Data Virtualization to query data from multiple data sources without creating data replica.
- Use IBM DataStage to create ETL pipeline
- Use IBM Data Refinery Flow to clean, and filter the data.
- Use IBM Watson Knowledge Studio to profile and govern the data.
- Supply the data to AI based predictive system such as Amazon SageMaker or Jupyter Notebook to create machine learning models.